RTX5090 체험 후기 (상) | Gcube 지큐브
최근 gcube RTX 5090 체험 테스트에 선정되어 무상으로 체험해보게 되었다.

그 논란의 물량도 얼마 없어 돈이 있어도 구하기 어려운 RTX 5090을, 심지어 무료로 말이다! 게다가 5090뿐만 아니라 4090, 5080도 함께 제공받았다. 모두 현시점에서 가장 성능이 좋은 소비자용 그래픽카드 3종류이다. 메모리가 작고 대역폭 병목을 제외한 성능만 본다면 현존 최고 성능이다.
이들 모두의 단정밀도 성능을 합하면 무려 243.66 TFLOPS이다. (104.8+82.58+56.28)
성능에 대한 부분은 이제 그만 비교하고 RTX 5090, 4090, 5080을 사용해본 후기와 Gcube 서비스에 대한 경험을 지금부터 공유해보려 한다.
들어가기 전에, 본 체험은 Gcube에서 주최한 이벤트에 당첨되어 진행되었음을 밝힌다.
우선 체험한 Gcube 플랫폼에 대해 간략히 설명해보겠다.
Gcube는 Vast AI와 같이 유후 GPU 자원을 공유하는 GPUaaS이다. 간단히 한국 버전의 Vast AI라고 생각해도 좋을 것 같다.
또한 Tier별로 사업자, 서버, 개인 등으로 나뉘어져 있고, 가격과 성능이 다르다.
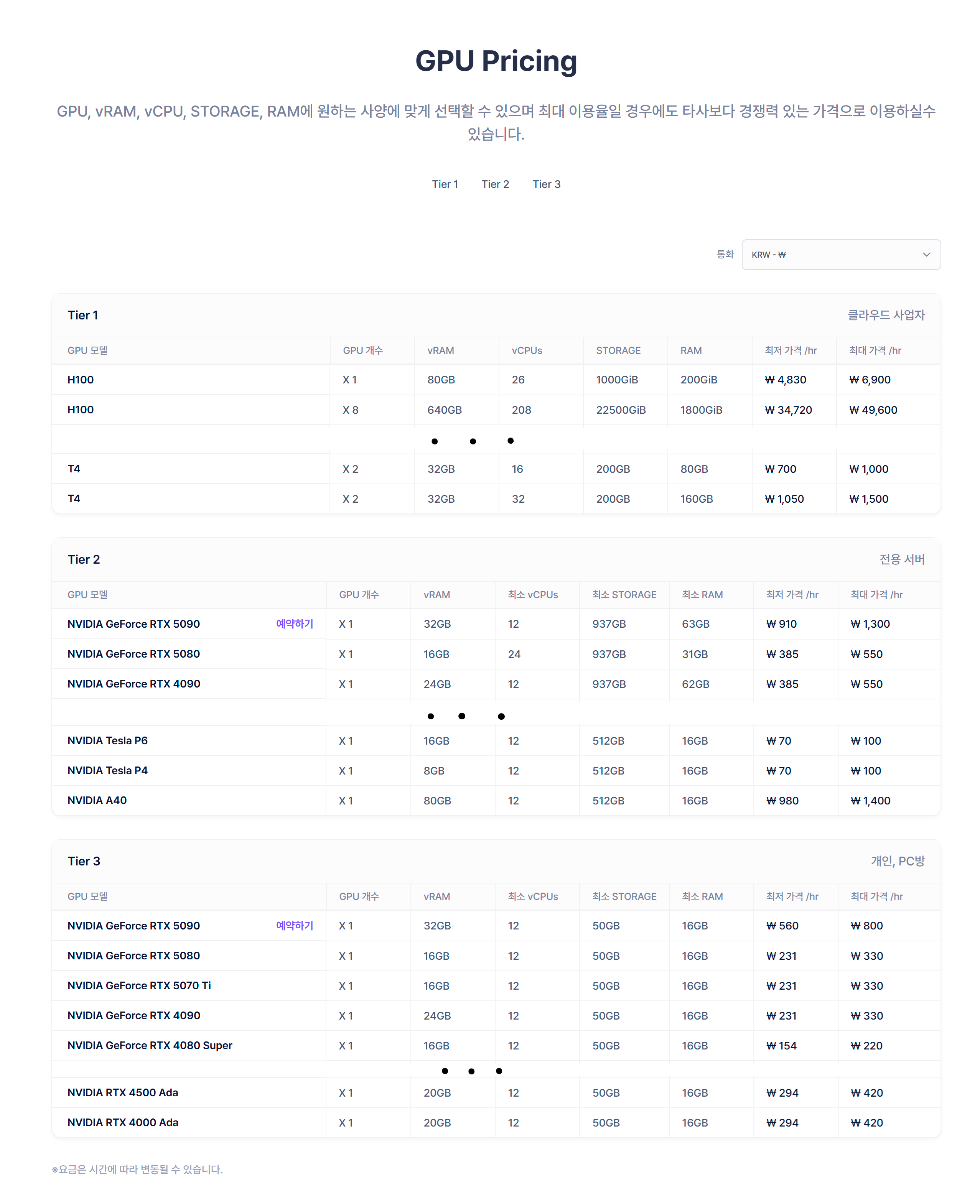
놀고 있는 자신의 그래픽 카드를 공유해 포인트를 벌거나, 포인트를 충전해 그래픽카드를 임대할 수 있다.
이정도 설명이면 충분했을 것 같다. 이제 진짜 시작해보겠다.
Gcube 플랫폼에 가입했을때는 깔끔한 디자인이 마음에 들었다.
그러나 인스턴스를 생성하는 방식이 약간 특이 했는데, 스펙을 선택하는 것이 기존의 VastAI 방식보다는 일반 클라우드 플랫폼과 비슷한 방식이었기 때문이다.

근데 또 스토리지랑 램 용량은 고정되어있었다. 물론 티어가 높으면 용량이 크긴 하지만 수정은 안된다.

약간 당황스러움이 있었지만, 아마 VastAI와는 타겟층이 달라서 용량 고정해둔 것으로 추측된다.
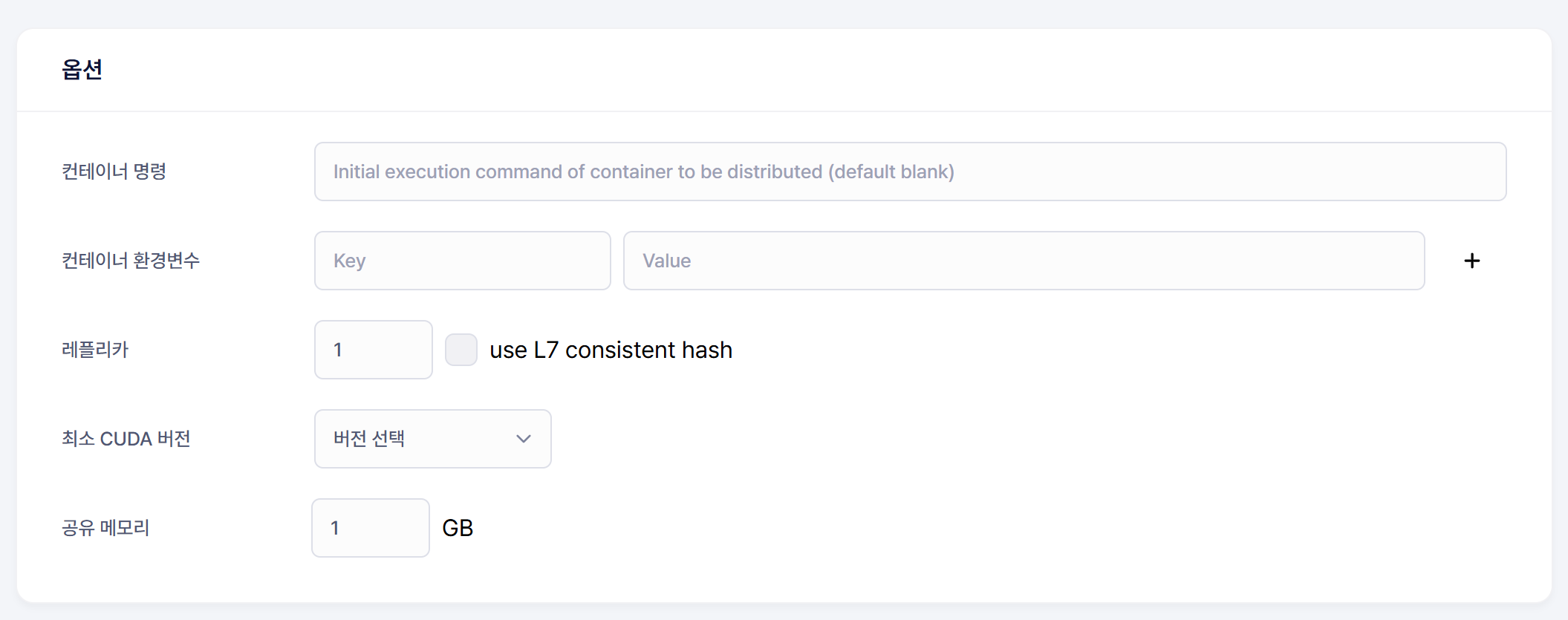
또, 리소스 공유는 컨테이너로 이루어지기에 컨테이너 이미지가 필요하다.
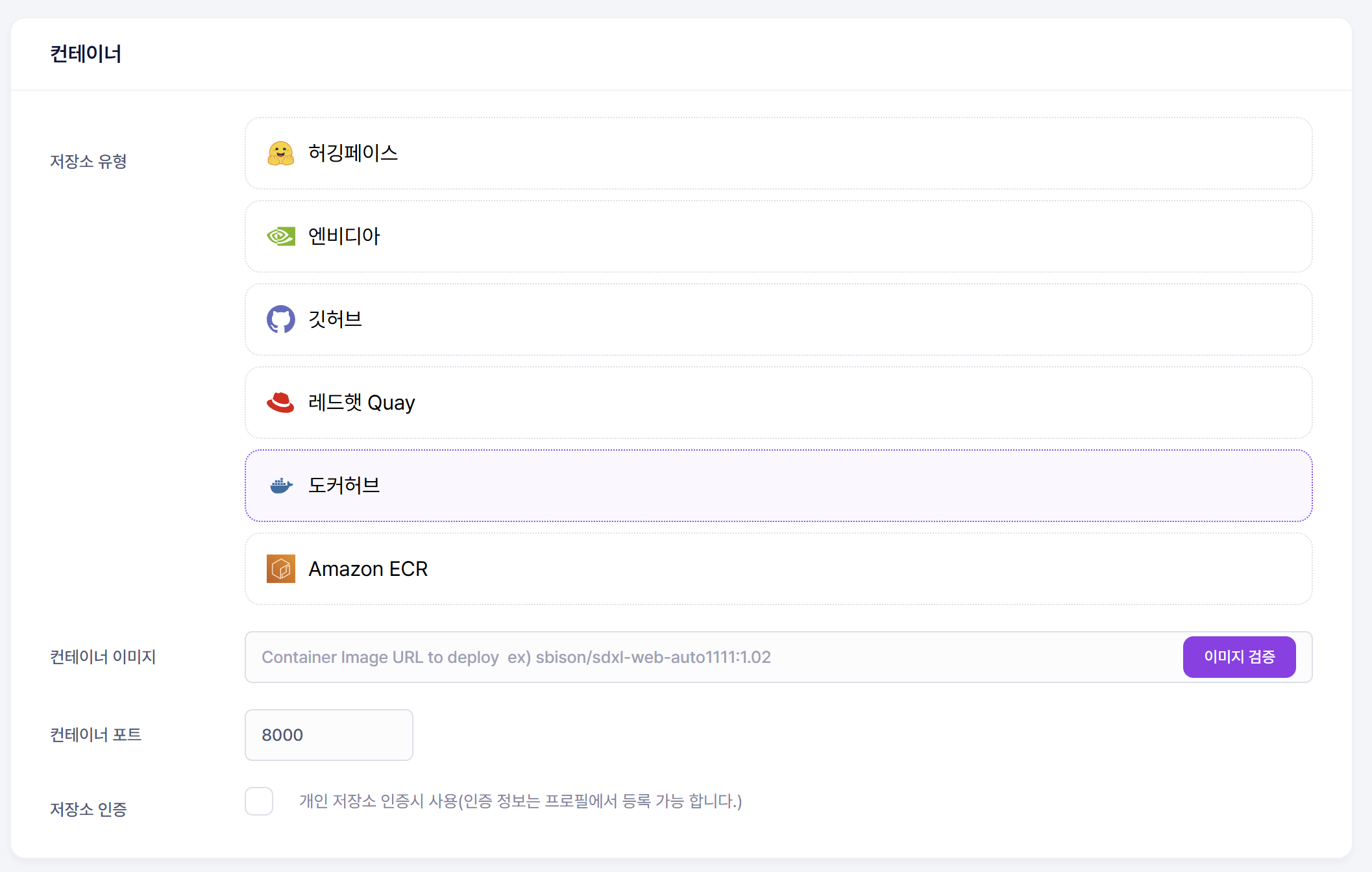
물론 샘플 도커 이미지도 있지만, 생성시에 선택화면에는 없고 문서에서 찾아봐야만 나온다. 약간의 편의성 개선이 추가되었으면 좋을 부분이기도 하다.
어쨌거나, 개발 환경이 포함된 컨테이너 이미지를 빌드하고 배포하면 사용할 수 있다.
사용가능한 이미지가 EXPOSE로 포트가 열려있어야 한다는 약간의 제한?이 있었지만 우분투에 쿠다를 올리고 주피터 랩으로 쉘을 사용하면 큰 문제는 없다.
(나중에 안 사실이지만 컨테이너에 SSH 연결도 가능하다! 근데 프록시 방식이라 특정 ip, 아이디, 비밀번호에서만 접속이 되고, ip가 바뀌면 또 등록해야한다..)
필자가 사용한 도커 이미지는 깃허브에 있으며, 간편해서 애용하는 Axolotl과 flash-attn이 모두 빌드되어 있다.
깃허브 > ghcr.io/deveworld/gpu-dev:cuda-12.8 을 이용하면 된다.
어쨌든 그렇게 이미지와 사양을 선택하고 배포하면 URL을 알려준다. 그 도커의 EXPOSE된 포트와 연결된 프록시 URL이다.
몇분 뒤면 주피터 노트북을 볼 수 있다.
쉘에서 axoltol fetch examples 를 통해 예시 yml 파일을 불러오고
axoltol train examples/gemma3/gemma-3-12b-qlora.yml 을 통해 gemma3 12b를 Quantizated LoRa 파인튜닝할 수 있고 5090에서 잘 돌아간다.
단일 GPU로 12B LLM을 파인튜닝할 수 있다니 얼마나 대단한가. 양자화와 최적화 덕분이다. 물론, 5090 메모리가 크고 파워가 센 것도 있지만 말이다.
그렇게 자체 데이터셋으로 Gemma3 1b, 4b, 12b를 동시에 5080, 4090, 5090에서 파인튜닝을 진행했다.
그리고 결과는..
유실되었다.
무료체험 마지막 몇시간 전에 주어진 포인트를 모두 써버려 멈추고 만 것이다. 추가 포인트를 제공 받았지만, 새벽이라 받은 것은 아침이 된 후였다.
물론 일정 steps마다 저장하고 push했어야 하지만, 설마~~ 라는 안일한 생각으로 그냥 훈련을 시작했었다.
모두 앞으로는 꼭 저장을 습관화하기를 바란다.. 귀찮다고 아까운 모델을 다 날리는 경우도 있다.
어쨌거나 3일동안의 5090 체험은 엄청난 파워의 gpu 성능을 체감하기에 충분했다.
다시 한번 Gcube에게 감사의 인사를 전한다.
Gcube 플랫폼은 배포가 간단했고, 무엇보다 한국이어서 파일 이동도 빨랐다. 기회가(돈만) 있다면 다시 쓸 것 같다.
지금 가입하면 5000P(=5000원)을 준다고 하니 사용해보지 않았다면 한번 체험해보는 것도 나쁘지 않을 것 같다.
이상 5090 체험 후기였습니다. 읽어주셔서 감사합니다.