KorT: LLM이 평가하는 한국어 번역 벤치마크
한국어 번역 품질 벤치마크 KorT를 출시했습니다!
최근 한강 작가님의 작품이 노벨 문학상을 수상하며 전 세계의 주목을 받았던 일을 기억하시나요?
사실, 상을 수상한 배경 뒤에는 좋은 번역이 있었습니다.
좋은 번역은 단순한 언어 변환을 넘어, 우리의 문화와 이야기를 세계 무대에 성공적으로 선보이는 데 결정적인 역할을 합니다.
이처럼 번역의 중요성은 점점 더 커지고 있는데, 과연 '좋은 번역'인지 아닌지는 어떻게 객관적으로 알 수 있을까요?
파파고, 구글 번역 같은 서비스들이 이미 우리 곁에 있지만, 어떤 번역이 더 나은지 정량적으로 비교하고 평가하기란 생각보다 쉽지 않습니다.
기존의 BLEU 같은 자동 평가지표는 은유나 문화적 맥락 같은 미묘한 차이를 잡아내기 어렵고, 사람이 직접 평가하자니 시간과 비용이 만만치 않습니다.
이런 고민 속에서 새로운 한국어-다국어 번역 품질 평가 기준, KorT(Korean Translation Benchmark) 를 만들어서 공개하게 되었습니다.
KorT는 최근 인기인 MT-Bench와 같은 'LLM-as-a-judge' 방식을 채택했습니다.
LLM의 뛰어난 언어 이해력을 빌려, 기존 자동 평가의 한계를 넘어서면서도 사람의 판단과 더 유사한, 아주 정교한 평가를 할 수 있게 되었습니다.
제대로 평가하기 위해서는 평가할 문장부터 좋아야합니다.
그래서 일부러 중의적인 표현, 관용구, 한국 문화가 담긴 문장처럼 번역하기 까다로운 문장들로 데이터셋을 구성했습니다.
실제 번역에서 부딪힐 법한 복잡한 문제들을 모델이 얼마나 잘 해결하는지 꼼꼼하게 따져보기 위해서입니다.
KorT가 추구하는 가장 큰 목표는, 기존의 기계적인 점수 매기기보다 사람의 평가 결과와 훨씬 더 비슷한, 믿을 수 있는 평가 체계를 만드는 것입니다.
그리고 이 평가 결과를 바탕으로 다양한 기계 번역(MT) 시스템과 LLM들의 한국어 번역 실력을 겨루는 공개 리더보드도 꾸준히 운영할 계획입니다.
이걸 통해 지금 번역 기술들이 어디까지 왔는지 한눈에 보여주고, 개발자분들께는 어떤 부분을 더 개선하면 좋을지 힌트를 드리고 싶습니다.
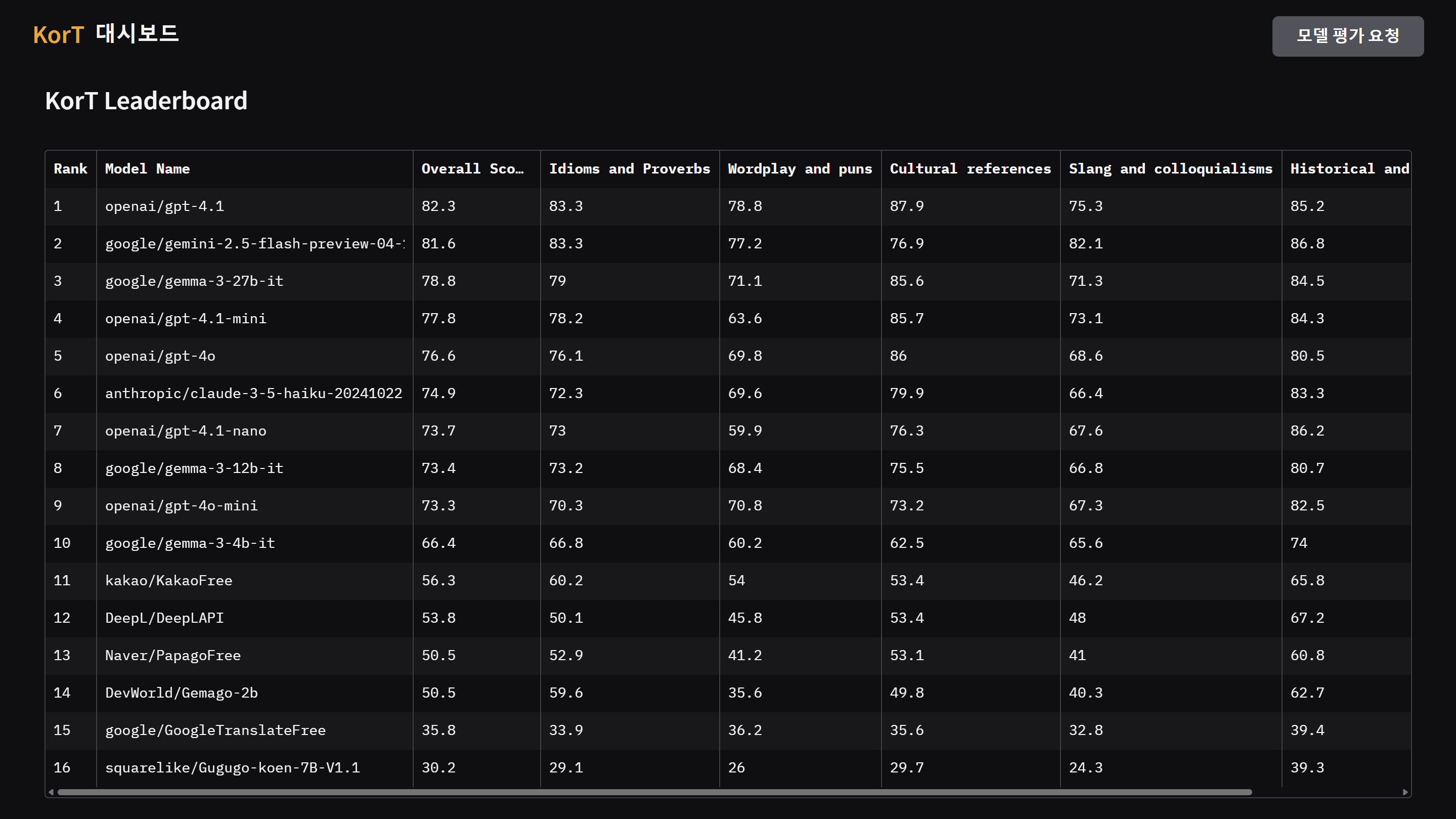
위 KorT 리더보드를 보시면 꽤 흥미로운 점들을 발견하실 수 있을 겁니다.
예를 들어, 어떤 종류의 문장 번역에서는 경량 LLM(가령 Gemma-3-4b 같은 모델)이 우리가 매일 쓰는 파파고나 구글 번역보다 더 나은 성능을 보여주기도 합니다.
KorT는 바로 이런 구체적인 성능 차이를 명확하게 비교해볼 수 있는 좋은 도구가 될 겁니다.
단순히 줄 세우기가 전부는 아닙니다.
KorT는 한국어 번역 기술의 강점과 약점이 무엇인지 깊이 이해하고, 특히 우리말의 섬세한 맥락을 잘 살리는 방향으로 기술이 발전하도록 돕고 싶습니다.
궁극적으로는 더 수준 높은 다국어 기계 번역 시대를 앞당기는 데 기여하는 것이 KorT의 목표입니다.
새롭게 선보이는 KorT 벤치마크와 리더보드에 많은 관심 부탁드립니다.
아래 링크에서 더 자세한 내용을 확인하실 수 있고, 사용해보시고 느끼신 점이나 개선 아이디어 등 어떤 피드백이든 많은 의견 부탁드립니다.
리더보드
깃허브
여러분의 의견은 KorT를 더욱 발전시키는 데 큰 힘이 됩니다.
읽어주셔서 감사합니다.