TPU Pods Gemma3 파인튜닝 정리
최근 구글이 출시한 Gemma3를 TPU Pods에서 파인튜닝해보기 위해 삽질중이다.
이 포스트는 삽질을 정리하기 위해 작성하고 있다.
요약
2025-03-20 gemma-llm으로 시도해보았지만 실패했다.
2025-03-21 Google Deepmind gemma-3 report 팀에 이메일을 보냈다. 답변이 없다
2025-03-22 🤗 Optimum TPU에서 파인튜닝이 되는 것을 확인했다.
EasyDeL 프로젝트 또한 사용 가능하다.
2025-03-26 keras-hub에 gemma3가 merged되었다. jax를 백엔드로 keras3를 사용하자.
이전에 Gemma v1 모델은 https://github.com/deveworld/Gemma-EasyLM/ 을 통해 파인튜닝 했으며, Beomi님의 Gemma-EasyLM을 기반으로 하였다.
간략하게 설명하자면 HuggingFace Transformers의 Flax Gemma Modeling을 이용한 것이다.
Gemma2 모델은 Keras3의 Keras-nlp, 현재 Keras-hub, 를 통해 파인튜닝 하고 있었다. (그러나 Gemma3가 출시되며 모두 엎어졌다...)
이제 Gemma3이 출시되었으니 Gemma3를 파인튜닝 하려고 시도해보려 했지만, HF에 Flax Modeling도 없고, Keras-hub에서도 아직 추가중이다. (keras-hub#2152)
그래서 이번엔 Google DeepMind의 공식 구현인 gemma-llm을 활용해 파인튜닝을 해보기로 했다.
그러나, 은탄환은 없는법이다. 단일 TPU VM에서는 (많은 종속성 에러와 함께) 동작하지만, TPU Pods에서는 드라이버 단에서부터 오류가 난다.
해결 방법을 찾기 위해 Gemma3 팀에 [email protected] 메일로 직접 컨택을 해보았다.
대충 `Gemma3 자체가 TPU Pods에서 학습된거 같은데, 어떻게 하셨나요? 다른 코드가 있나요?` 정도의 내용이었다.
물론 아직까지 회신은 없다.
그래서 회신이 오기전까지 이것저것 알아보던중 torch/xla 위에서 돌아가는 🤗 Optimum TPU를 발견했다!
좀 유기된 프로젝트 같지만 이걸로 시도해보기로 했다.
물론 Gemma 1까지만 지원하지만, Gemma3를 처음부터 Flax Modeling 하는 것 보단 나을 것이다. 필자가 Model 아키텍처를 Flax로 짜본 경험도 없고 말이다. 무엇보다 귀찮다.
우선 대충 코드를 보고 gemma3도 포함하게 바꿔준다. (나중에 알고보니 모델 타입이 gemma3_text 였다.)
이후 간단하게 exmaples 코드를 참조해서 작동하는지 확인해보았다.
import torch
from peft import LoraConfig
from trl import SFTTrainer, SFTConfig
from transformers import AutoTokenizer, AutoModelForCausalLM
from optimum.tpu import fsdp_v2
from datasets import load_dataset
fsdp_v2.use_fsdp_v2()
model_id = "google/gemma-3-4b-pt"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype=torch.bfloat16)
def preprocess_function(sample):
instruction = f"### Instruction\n{sample['instruction']}"
context = f"### Context\n{sample['context']}" if len(sample["context"]) > 0 else None
response = f"### Answer\n{sample['response']}"
# join all the parts together
prompt = "\n\n".join([i for i in [instruction, context, response] if i is not None])
prompt += tokenizer.eos_token
sample["text"] = prompt
return sample
dataset = load_dataset("databricks/databricks-dolly-15k", split="train")
data = dataset.map(preprocess_function, remove_columns=list(dataset.features))
# Set up PEFT LoRA for fine-tuning.
lora_config = LoraConfig(
r=8,
target_modules=["k_proj", "v_proj"],
task_type="CAUSAL_LM",
)
# Set up the FSDP arguments
fsdp_training_args = fsdp_v2.get_fsdp_training_args(model)
# Set up the trainer
training_arguments = SFTConfig(
run_name="gemma3-optimum-tpu-test",
dataset_text_field="text",
per_device_train_batch_size=64,
num_train_epochs=32,
max_steps=-1,
output_dir="./output",
optim="adafactor",
logging_steps=1,
dataloader_drop_last = True, # Required for FSDPv2.
max_seq_length=1024,
packing=True,
**fsdp_training_args,
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=data,
peft_config=lora_config,
)
trainer.train()결과는...
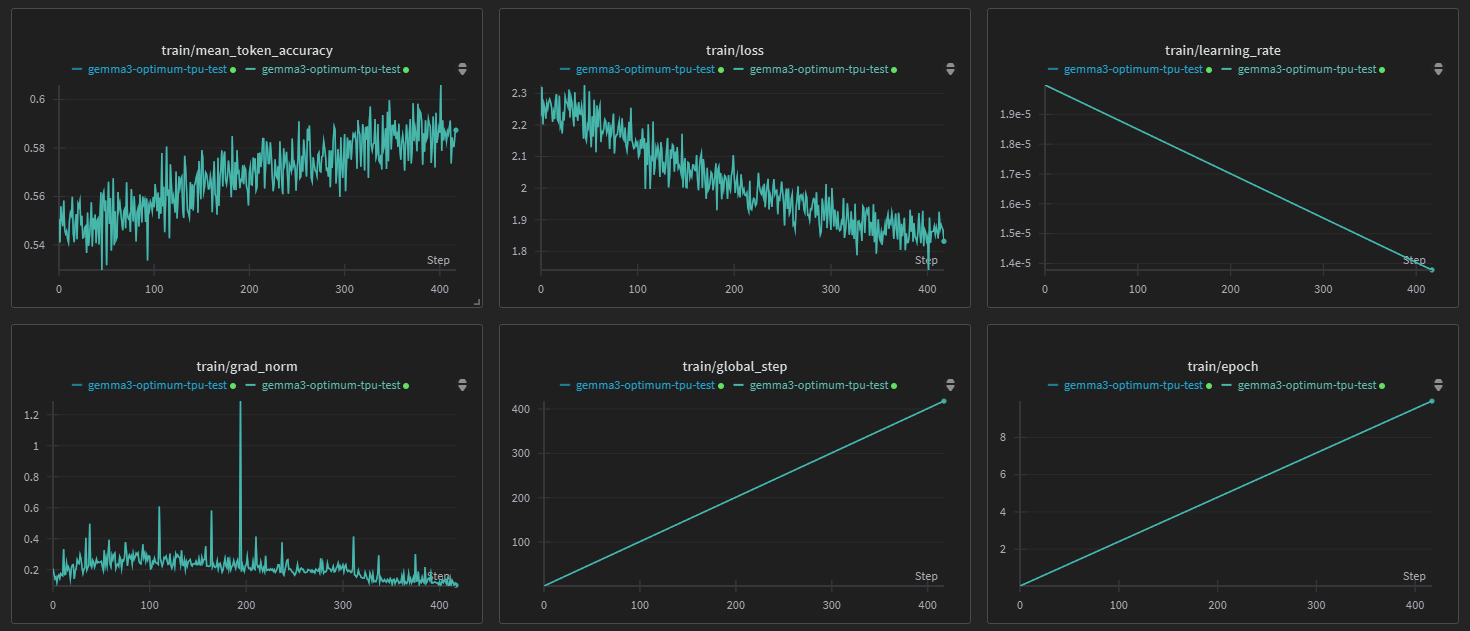
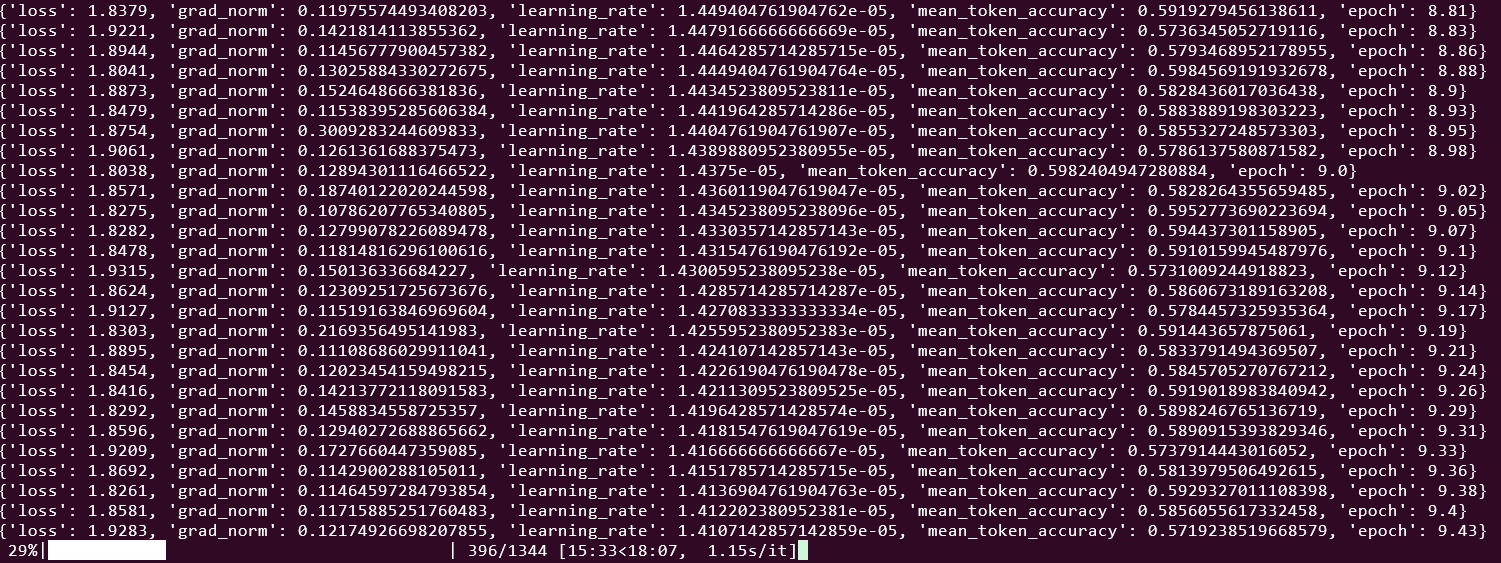
잘 된다! 좀 느린 느낌이 있지만 어쨌든 된다!
학습은 되지만 Optimum-tpu에서 `Optimum-TPU support and is optimized for v5e and v6e TPUs.` 라고 한 만큼 TRC에서 제공받은 v4 TPU에서는 아직 종속성 문제도 많다.
조금 더 살펴본 다음 Warmup Cosine Decay도 달고 Dataset도 불러오게 해서 코드를 깔끔하게 짜야겠다.
Gemma3는 아직 출시된지 얼마 안되서 하이퍼 파라미터도 건드리면서 나은걸 찾아봐야 한다.
그런 와중에 EasyDel이라는 JAX 기반 프레임워크를 발견했다.
다른 분들이 이미 Flax로 Gemma3를 모델링 해놓은 것이다. (감사합니다 ㅠㅜ...)
심지어는 Mistral, Phi3부터 Exaone까지 전부 있다..!!
그러던 와중 keras-hub에 Gemma3 feat가 merge되었다.
그냥 깔끔하게 전처럼 keras3를 써서 finetune 하는 것이 제일 나을 것 같아 보인다...